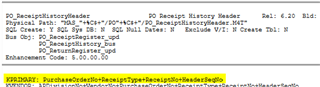
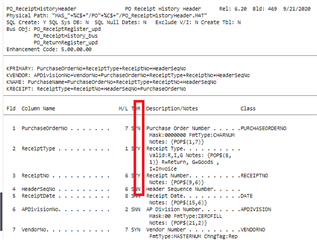
Running Sage 100 v2018. We receive an import file containing AP Invoice information. Within the import file there is a Purchase Order number. I am trying to figure out a way to match the PO number from the import with the PO number within the PO_ReceiteHistoryHeader and, if there is a match, populate the Invoice Number from the import file into the PO_ReceitHistoryHeader table.
I am aware of the ramifications of adding data to a history file but this is a unique situation where the main company contains the pertinent, unmodified information and the company we're writing the information to is strictly for identifying information within the Purchase Order Receipt History Report.
Example ---
File containing data to import and two import records::
InvoiceNo,InvoiceType,APDivisionNo,VendorNo,PurchaseOrderNo,ReceiptDate
1234567,I,00,1426548,0042229,20210520
1234568,I,00,0005383,0052258,20210522
Need to:
1) Using the above example file, scan through PO_ReceiptHistoryHeader table looking for a PurchaseOrderNo that matches field 5 of the import file
2) If a match is found, populate the InvoiceNo field of PO_ ReceiptHistoryHeader with the InvoiceNo (field 1 of the import file)
3) Move onto the next record in the import file and repeat steps 1 and 2